初试大数据处理--个人聊天记录的存储与检索
前一阵子写了个小东西把我的所有聊天记录备份到了数据库,没想到备份完之后数据意外的多,光文本加起来已经超过 5 亿行了,sqlite 检索起来也有些力不从心,于是在考虑要不要换成服务器数据库。
花了两天导入到了 mysql,又花了大半天建立索引,单次查询速度终于缩减到一分钟左右,但是存储容量已经超过 100g 了,于是开始查查有什么办法能压缩下。最开始尝试了用 Compressed Row,压了两三个小时候从 121g 缩减到 76g,看起来还行,但是相比之前 sqlite 的 57g 还是大了不少,应该是索引太占空间了。
后来发现 tidb 的压缩率似乎不错,于是又开始把数据倒腾过去。tidb 单机部署不太友好,用 docker 是相对方便的,tidb 默认使用 3 个 tikv 存储用于容错,但是对于单机应用就没什么必要了,直接把 tikv 和 pd 砍到一个,然后导入数据,这次速度比较快,大概是 mysql 的读取速度还可以,最终数据量减少到 45g,终于比 sqlite 小了,但问题是 tidb 整一套东西太占资源了,空跑都至少吃一个核心。
在尝试 tidb 的时候看了很久文档,发现他还有个叫 tiflash 的列存引擎,号称压缩率可以达到更高,适合读多批量写多的分析场景,这不是跟我的使用场景很适合么?但是仔细看了下文档,现在并不支持只使用 tiflash 作为后端使用。于是进一步查询,发现了 clickhouse 这个专精查询的列存数据库,是由俄罗斯的搜索引擎巨头 yandex 开发和开源的。
于是把服务器下回来部署,官方没有提供 mac 的自动部署,但是有提供二进制文件手动部署,看了下整个服务器只有一个二进制。很对我胃口。不过看到有 docker 镜像,就懒得手动部署了,直接 docker 跑起:
docker run -d --name clickhouse --ulimit nofile=262144:262144 \
--volume=$HOME/.database:/var/lib/clickhouse:delegated yandex/clickhouse-server
这里 volume 的挂载加了个delegated的 flag,可以大幅提升挂载路径的读写性能,缺点是文件管理器里的文件刷新不及时,经过测试,同一个表(Delta+ZSTD(5))导入,带delegated比不带的速度可以提升三倍以上,可惜这个 flag 似乎只支持 mac。
之后就是用 client 连接过去,这里依然使用 docker 版本,直接把容器 link 起来就可以连接了:
docker run -it --rm --link clickhouse:clickhouse \
yandex/clickhouse-client --host clickhouse
之后就是创建表和迁移数据了,首先创建一个新表:
create table "database"."table" (
timestamp DateTime CODEC(Delta, ZSTD(5)),
content String CODEC(ZSTD(9))
) engine=MergeTree order by timestamp
由于列存引擎是按列存储的,对于相同数据和类似数据的压缩率很高,于是我所有的标识,譬如账号、群组、发信人、收信人之类的全部整合到一张大表里了。
这里值得一说的是想 timestamp 这种递增的数据我用了 Delta 编码去编码,然后再用 ZSTD 去压缩,还有账号群组这种重复性很高的列,用了 T64 和 ZSTD 压缩,数据越长的话可以考虑用更高的压缩档次,我在内容和链接当前行对应 blob 的列使用了 ZSTD9,其他全部使用 ZSTD5。
设计好表之后进行数据导入,clickhouse 直接支持从多个数据库导入或者同步数据,这一点很友好,因为我不考虑保留其他数据库了,所以直接导入:
insert into "database"."table"
select * from mysql(
"host.docker.internal:3306", "database",
"table", "root", "password"
);
因为 mysql 也在本机,所以直接用host.docker.internal可以从容器连接到物理机,在我的导入场景里,基本可以达到每秒钟 10w 行:
导入

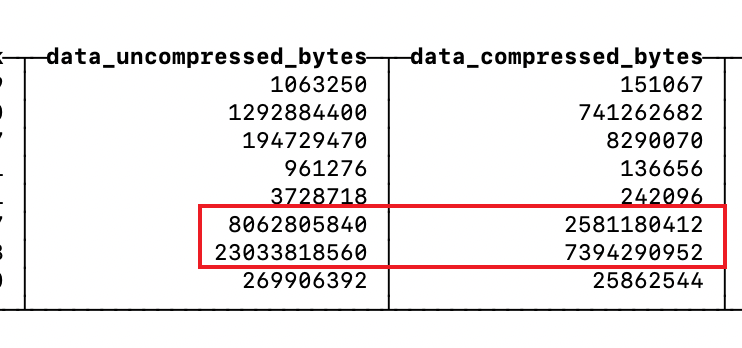
这次只花了一个小时多一点导入完了,看了下压缩率十分吓人,经过编码未压缩前的数据是 31g 左右,压缩后只有 10g 左右,刚开始还以为是导入漏了数据,于是导出成 csv 跟 sqlite 的表做对比,发现没有任何遗漏:
表大小
作为对比,对原始 sqlite 库进行最高压缩档的 lzma 压缩后,仍然有 17g:
lzma

最后做一下查询测试,没有做索引,使用时间戳作为主键,搜索我的聊天记录中的一行:
查询

总共花了 83 秒,实际上搜索了不到十秒就已经搜到了并打印出来了,如果 limit 1 的话 10 秒就能结束搜索。
数据迁移到此结束,还剩下的课题就是如果做多点备份,以及对落盘数据加密,之后如果有结果会再写一篇文章。